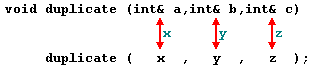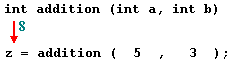
The return value of main
You may have noticed that the return type ofmain is int, but most examples in this and earlier chapters did not actually return any value from main.Well, there is a catch: If the execution of
main ends normally without encountering a return statement the compiler assumes the function ends with an implicit return statement: |
|
Note that this only applies to function
main for historical reasons. All other functions with a return type shall end with a proper return statement that includes a return value, even if this is never used.When
main returns zero (either implicitly or explicitly), it is interpreted by the environment as that the program ended successfully. Other values may be returned by main, and some environments give access to that value to the caller in some way, although this behavior is not required nor necessarily portable between platforms. The values for main that are guaranteed to be interpreted in the same way on all platforms are:| value | description |
|---|---|
0 | The program was successful |
EXIT_SUCCESS | The program was successful (same as above). This value is defined in header <cstdlib>. |
EXIT_FAILURE | The program failed. This value is defined in header <cstdlib>. |
Because the implicit
return 0; statement for main is a tricky exception, some authors consider it good practice to explicitly write the statement.